-
在银行做DevOps
几个月前, 我换到了现在的DevOps team, 与Dev, QA, Ops一起, 运维一个庞大的银行前台系统.
做什么?
DevOps是什么? 有人玩笑说: 开发者做运维.这的确是我的经历, 之前是developer, 现在做ops. 几个月下来,我所理解的DevOps: 负责代码提交之后的工作: 提供打包,测试,发布,生产环境监控/支撑一条龙服务.
今天聊聊测试与发布.
提供测试服务 Test as a Service
跟很多团队一样, 我们也在努力的实践TDD, BDD. 新的功能应该从feature file开始, 不断的迭代、验证, 而不是先开发后验证. DevOps团队需要支撑测试, 提供测试所需的工具与环境.
开发测试套件
对于很多早已上线的App以及Legacy系统, 我们需要从新增加feature test来确保其正常运行. 这些feature test往往需要非常深厚的专业知识, 所以不管是Dev,Ops还是DevOps, 都写不了feature file. 这些工作由BA(Business Analyst)负责. 他们会与最终用户沟通需求, 然后编写Gherkin feature file.
有很多敏捷团队会提倡
Wearing Multiple Hats, 或者说人人都是Developer(前几年我在摩根大通工作时, 很多团队就提倡人人都是developer). 这样的做法可能适合某些场景, 但是在某些专业领域并不适用: 有些产品太过专业, developer/coder只能了解一部分功能, 而不能整体把握整体的商业流程.但BA不会写代码, 我们也不能跟在BA后面等feature test写好再实现, 所以DevOps开发测试套件, 内置测试所需的大部分语法, BA只需要根据已有的语法, 就能独立编写并运行测试.
支撑测试环境
我们对测试环境有近乎生产环境的苛刻要求. 因为有些重要的测试会耗费大量资源(譬如: 几千个核), 或者耗费大量时间(几小时)
我很羡慕那些能够完全自动化的系统, 一个command就可以把整个系统部署起来. 很可惜, 我们的系统有太多的依赖: 依赖庞大的数据库, 消息队列, 下游系统. 一个标准的测试环境需要一个集群, 为了保证测试准确性, 应用程序, 数据库, 下游系统都需要整齐划一的运行.
即使存在这么多的限制, DevOps还是要尽多尽早的部署新的release candidate. 为了规避来自其他服务或应用的风险, DevOps会尽可能多的监控测试环境.
CI
除了开发测试套件与支撑测试环境, DevOps还会维护一个CI服务, 以便BA可以自己配置CI工程, 来运行他们的测试. TeamCity是一个不错的选择, 相比Jenkins, TeamCity对非技术人员更友好一些.
发布 Release
在银行工作过的同学都应该了解, release不是想做就能做的. 需要根据合规/审计部门的要求, 提前计划, 获得层层批准. DevOps需要在规定时间内完成所有操作. 如果需要手动的复制文件, 手动的安装应用, 那将会一场噩梦. 我们使用Python根据内部需要, 开发了自动化发布系统, 除此之外, 我们也通过减小测试环境与生产环境的差别来降低风险.
我们的部署工具随着一次次的部署而不断改进, 在这一过程中, 我们学到很多经验, 如:
- 不要假设生产环境会有怎样的配置. 如果有疑问, 应该尽早确认
- 消除一切能消除的生产/测试环境差别
- 不要存在重复代码, 看似复制粘贴很快, 实际上就是在挖坑
- 减少
if...else...尤其是在配置文件中, 如:if env.is_prod()...else..., 因为这样的代码没法在生产环境之外测试
话题
缩小Feedback loop, 每个人都是受益者, 每个人都需要参与
如果你是一个developer, 有没有想过这个问题: 既然有integration test, 我们还需要写unit test吗? 我相信很多人都像曾经的我一样, 认为既然有足够的integration test就能保证万无一失, unit test并不是必须的.
如果project变大变复杂, 你就会发现, 不写unit test的成本是很高的: 假如小明不小心增加了一个bug, 如:
amount_in_sgd = amount_in_usd * rate_usd_cny(新币金额 = 美元金额 * 美元对人民币汇率). 小明赶进度, 没写测试就check-in, 小花也忙着自己的工作, 扫了一眼, 就批准了小明的代码, 是bug就进入了系统. 紧接着, 系统build(5分钟), 基本测试(15分钟)通过. 小明已经全力以赴的开始了下一个task. 基本测试成功后的artifact被部署到测试环境中, 连接上下游系统, 开始跑集成测试, 40分钟之后, 小明收到邮件, 从进行到一半的任务中抽身回来检查bug.(Context switch) 这个feedback花了60分钟才收到! 这还是理想情况, 如果中间夹杂有任何的异常, 这个feedback都会被拖延. 而且这里有一个假设: 集成测试涵盖了所有的测试项目. 如果这样的bug没有在集成测试里发现, 恐怕到生产环境, 用户才会发现, 这时候这个feedback就升级成了production issue.所以测试要早做, 离production code越近越好. 小明如果编写UnitTest, 他就可以在几秒钟之内获得feedback. 有效的规避之后的context switch以及其他风险. 在现实生活中也是这样: 假如你买到一辆发动机有问题的汽车, 你会是什么感觉? 你可能会很生气, 因为汽车厂商没有做好他们该做的: 测试并保证质量. 如果你是负责发动机的工程师, 你一定会在发动机装进整车之前就做好测试. 对DevOps来说, 更是这样. 我们不会假设一个release candidate是完美的, 所以先会把release candidate放到一个CI环境里去跑, 快速部署, 快速测试, 尽量缩小feedback loop.
协作
在设计新功能时, Development team应该从尽早邀请DevOps/Ops介入, 至少进行Design Review, DevOps会站在不同的立场上来看待每一个新功能, 提出建议. 这些建议往往对于系统的维护运行都很重要, 一个没有兼顾到Ops的设计, 很可能是在埋坑.
重写还是重构 Rewrite or Refactor?
“这个application写的太烂了, 我们应该从头开始重新写”
听起来拫熟悉吧? 总会有人(尤其是新人)无法忍受旧的程序, 提议重新来过, 可问题是: 真的需要吗? 以我的经验, 这大多时候是在用另一种语言/框架来犯相同的错误.
Jel on software: It’s important to remember that when you start from scratch there is absolutely no reason to believe that you are going to do a better job than you did the first time. First of all, you probably don’t even have the same programming team that worked on version one, so you don’t actually have “more experience”. You’re just going to make most of the old mistakes again, and introduce some new problems that weren’t in the original version.
-
纽约将立法禁止雇主在面试时询问应聘者薪资, 即使去不了纽约, 你也应该学会拒绝透露目前薪资
"你现在的薪资结构是怎样的?"这是一个你不想回答却难以避免的问题. 因为答案会在很大程度上决定你将要获得的薪水. “雇主”会根据你目前的薪资水平来确定你将要获得的薪水. 这听起来好像有点道理, 但却很不公平.小明与小刚同时毕业, 小明第一份工作就低于市场水平, 如月薪4000(
underpaid), 而小刚的薪水则正常水平, 月薪5000. 之后两人同时申请另一家公司的工作. 在面试中, 两人如实向对方透露目前薪水. 两人均面试出色, 拿到工作, 两人薪水涨幅20%, 小明薪水: 4800, 小刚薪水: 6000. 此时两人月薪差距: 1200. 假如小明与小刚每两年换一次工作, 且每次两人涨幅均为20%, 请问在工作十年后, 每月小明会比小刚少收入? 答案是(5000 - 4000) * 1.2^5 = 2985元/月小明的每一次换工作都像是在循环, 从一份
underpaid的工作到另一份underpaid的工作, 只是因为第一份工作接受了偏低的薪水, 十年后, 小明就要比小刚每月少收入近3000元.小明与小刚的故事不仅发生在我们身边, 也发生在不同地方, 不同性别, 不同种族之间, 周而复始的上演.
The financial industry – New York City’s largest employer – has one of the widest gender pay gaps at 6.4 percent. But it’s not the worst, according to Glassdoor’s adjusted data. Tied for that dubious honor are the health-care and insurance industries, where the adjusted gender pay gap is 7.2 percent. 引用来源: bloomberg.com
4月5日, 纽约市议会投票通过公共倡导者Letitia James的提议:禁止雇主询问应聘者之前的薪资状况. 以此结束低薪水的无限循环. 该项提议将会影响到约380万人.
“Being underpaid once should not condemn one to a lifetime of inequity,” said Public Advocate Letitia James. “Today, the New York City Council passed my bill that will ban employers from asking about previous salary information, a practice that is known to perpetuate a cycle of wage discrimination. We will never close the wage gap unless we continue to enact proactive policies that promote economic justice and equity.” - See more at: http://pubadvocate.nyc.gov/news/articles/groundbreaking-equal-pay-legislation-passes-new-york-city#sthash.MBQIfA1U.dpuf
我该怎样从低薪(Underpaid)循环中拯救自己?
天无绝人之路, 我觉得可以从以下几个方面突破:
- 去纽约找工作
- 做人大代表/议员, 提议当地政府也效仿纽约, 立法禁止雇主在面试时询问薪水
- 在下一次换工作时, 拒绝透露当前薪水.
相信对于大部分人, 只能选择最后一条路.
如何处理HR的问题: 你现在的薪资结构是怎样的?
毕业十年, 换过几次工作, 跟大大小小的十多家公司谈过薪水. 不得不说, 薪水谈判是一个很
蛋疼的过程. 在薪水谈判时, 我觉得最重要的一点是: 要坚强, 不要天真. 即使你迫切的需要下一份工作, 也要笃定的坚持, 更不要天真的相信对方说的每一句话.你现在的薪资结构是怎样的?这个问题一般是在面试前期, 或者是临近出Offer时被HR问到. 在开始申请工作前, 最好想透彻自己该怎么回答这个问题, 否则很可能会慌不择言, 透露不该透露的信息. 以下内容仅供参考:
- Say No 直截了当的回答: “抱歉, 我不方便透露”; 如果HR还是继续坚持, 下一步:
- 继续迂回 “我更倾向于公司根据我将带来的价值来确定我的薪水, 而不是根据我目前的薪水, 所以我觉得没必要透露”. 如果对方还坚持说: “这是公司必须的流程, 否则没的话没法继续后面的流程.” 参考下一步:
- 坚持自己的立场 “抱歉, 我很难理解这样的流程, 但是我还是不愿透露我目前的薪水, 我相信公司会根据我的价值而定义我的薪水.”, 如果HR还在纠结:
- 适度让步 “如果您想确定我们的彼此的期望是不是相符, 不如您透露一下这个职位的薪水预算?”. 对方很可能不会告诉你.
-
我最后的底线: 最多向对方说一个我认为合理的数字 譬如:”我的期望的底薪(basic salary)是20万人民币/年,我可以负责的告诉您, 这是一个合理的数字.”. 我的最后底线就是一个数字, 这是我对自己的定价, 可能是10%的涨幅, 也可能是30%甚至更多. 要考虑很多因素: 市场行情, 目前的薪资构成, 日后要做的工作, 交通, 等等. 至少要保证这个数字让你开心的开始下一份工作.
在给出我的底线(已经让自己处于劣势)之后, 如果对方还在耍那一套所谓的”公司流程”, 那我会告诉对方: “既然这样, 我想我不能适应贵公司的企业文化, 请帮忙取消我的面试”. 相信我, 如果他们预算足够, 一定会让你继续. 如果他们没有足够的预算, 或者根本没有那么迫切的需要招人, 那对你来说, 根本没必要跟他们浪费时间.
请注意, 这是
我的最后底线, 不代表你也需要这么做.
V2EX上有过类似的一个讨论, 可以参考:HR 电面问现在月薪怎么办
-
JDK HashMap中的算法(1): 获得等于或大于指定整数的2次冥
问题: 给定一个整数, 计算等于或大于这个整数的第一个2次冥
举例: 输入12, 输出16
解决思路:
- 循环, 直到找到下一个2的冥次方
for each int from i to MAX: if isPowerOfTwo_1(i) => return i在 is_power_of_2()复杂度为
O(1)的情况下, 这个解决方案的复杂度为:O(n), 如:public boolean isPowerOfTwo_1(int n) { return (n > 0) && (n & (n - 1)) == 0; }- 使用Bitwise操作
如果n是2的冥, 二进制表示会是这样:
2^0 1 = 0001 2^1 2 = 0010 2^2 4 = 0100 2^3 8 = 1000因此, 给定一个
1***, 只要拿到1111, 然后再加1就可以得到结果. 可以使用Bitwise的移位与或操作/** * Returns a power of two size for the given target capacity. */ static final int tableSizeFor(int cap) { int n = cap - 1; n |= n >>> 1; n |= n >>> 2; n |= n >>> 4; n |= n >>> 8; n |= n >>> 16; return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1; }- 一开始的
n = cap - 1操作是为了应对cap已经是2次冥的情况, 这样就可以统一处理; - 注意边界值:如果输入为0, Bitwise操作结束后,
n = -1
在
HashMap中,tableSizeFor()用于根据传入的initialCapacity计算capacity. 如map = HashMap(initialCapacity=20, loadFactor=0.8f),capacity将会在resize()时被设置为tableSizeFor(20)的结果,32. -
How HashMap works in Java
How many times have been asked this question in your job interview? for me, more than 10. I want to be crystal clear about this question to save everyone’s time.
How HashMap works in Java?
HashMapis akey-valuepair container based on hash table. it usually acts as a binned(bucketed) hash table, but when bins get too large, they are transformed into bins ofTreeNodes. a typical HashMap looks like: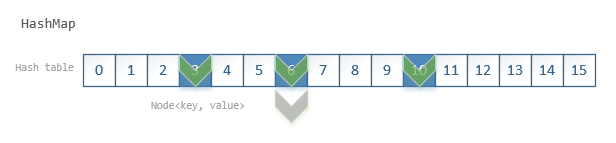
the hash table
the
tableacts as the index, initialized on first use, e.g.put(key, value). the default capacity is16.let’s say we initialized a map:
Map<User, String> map = new HashMap<>(), and now we want tomap.put(user1, "emai-add")first thing for aputis to identify the location in thetable. which cell should we put theNode<key, value>?identify index in the hash table
// Computes key.hashCode() and spreads (XORs) higher bits of hash to lower. hash = (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16) index = (table.length - 1) & hashthe
indexis calculated from thekey.hashCode(), and the tablelength.h >>> 6spreads higher bits of has to lower:the table uses power-of-two masking, sets of hashes that vary only in bits above the current mask will always collide
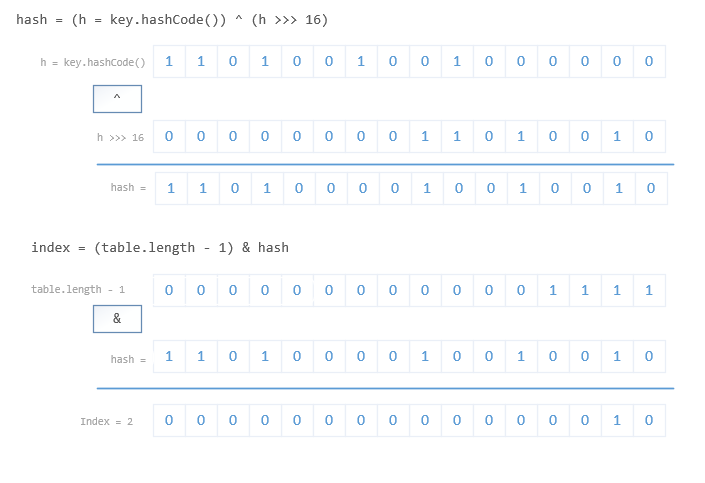
attache the node
if the cell
table[index]is empty, we can directly put aNode(key, value), e.g.table[index] = newNode(hash, key, value, null);if the cell already occupied, check the nodes and update/insert new node:
p = table[index] Node<K,V> e; K k; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else { for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } if (++size > threshold) resize();the key-value pair
Node<user1, "eamil-add">is attached on the hash table now.at the end of
putmethod,HashMapwill check whether it needs aresize()resize if necessary
power-of-two expansion, elements from each bin must either stay at same index, or move with a power of two offset in the new table.
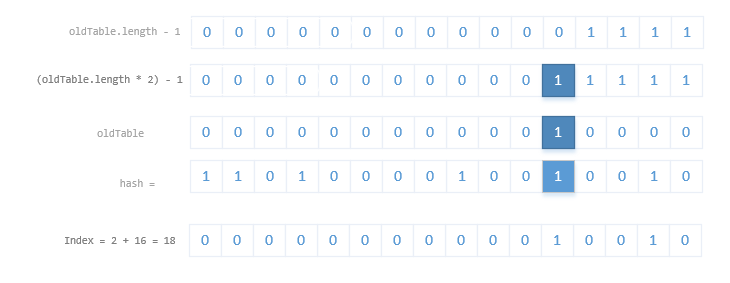
@SuppressWarnings({"rawtypes","unchecked"}) Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; table = newTab; if (oldTab != null) { for (int j = 0; j < oldCap; ++j) { Node<K,V> e; if ((e = oldTab[j]) != null) { oldTab[j] = null; if (e.next == null) newTab[e.hash & (newCap - 1)] = e; else if (e instanceof TreeNode) ((TreeNode<K,V>)e).split(this, newTab, j, oldCap); else { // preserve order Node<K,V> loHead = null, loTail = null; Node<K,V> hiHead = null, hiTail = null; Node<K,V> next; do { next = e.next; if ((e.hash & oldCap) == 0) { if (loTail == null) loHead = e; else loTail.next = e; loTail = e; } else { if (hiTail == null) hiHead = e; else hiTail.next = e; hiTail = e; } } while ((e = next) != null); if (loTail != null) { loTail.next = null; newTab[j] = loHead; } if (hiTail != null) { hiTail.next = null; newTab[j + oldCap] = hiHead; } } } } } -
Setup local Jekyll environment in 10 minutes using Vagrant + VirtualBox
If you’re not a Ruby developer and you don’t want to spend hours to setup your local Jekyll environment, you may consider to use a
Vagrantto automate this setup.Just in case you have no knowledge to
Vagrant: it’s an open-source tool for “building complete development environments”, we’ll use it together withVirtualBoxto start and config your local environment. you may view all the ‘InfrastructureAsCode’: https://github.com/guoliang-dev/jekyll-vagrant/blob/master/VagrantfileThat’s all!
useful links
 上图来自
上图来自subscribe via RSS